jeecms 爬虫 1.1beta版(2011-11-15)
=============================1.1版更新主要记录=========================
新增下载图片至本地功能,
新增过滤内容中链接功能,
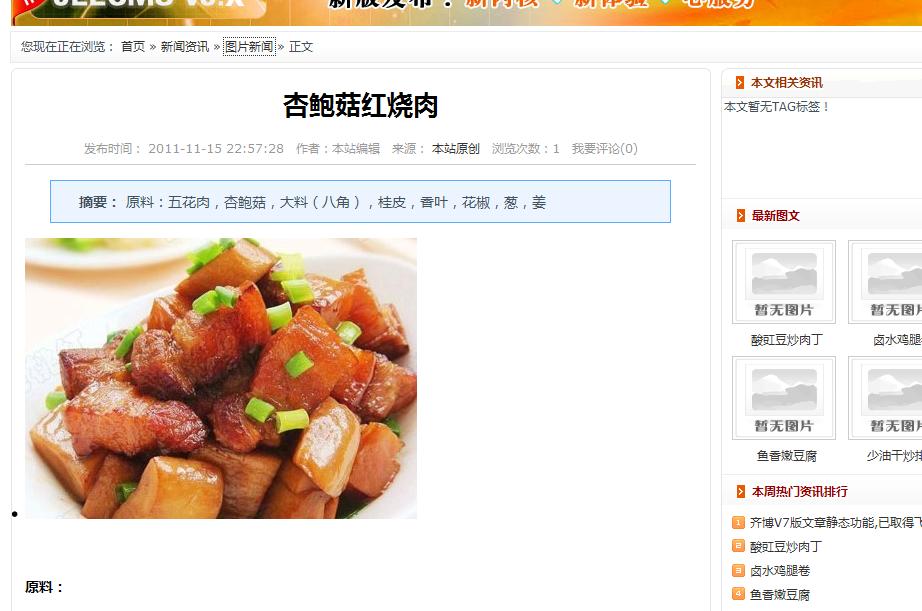
如图:采集 美食网 效果
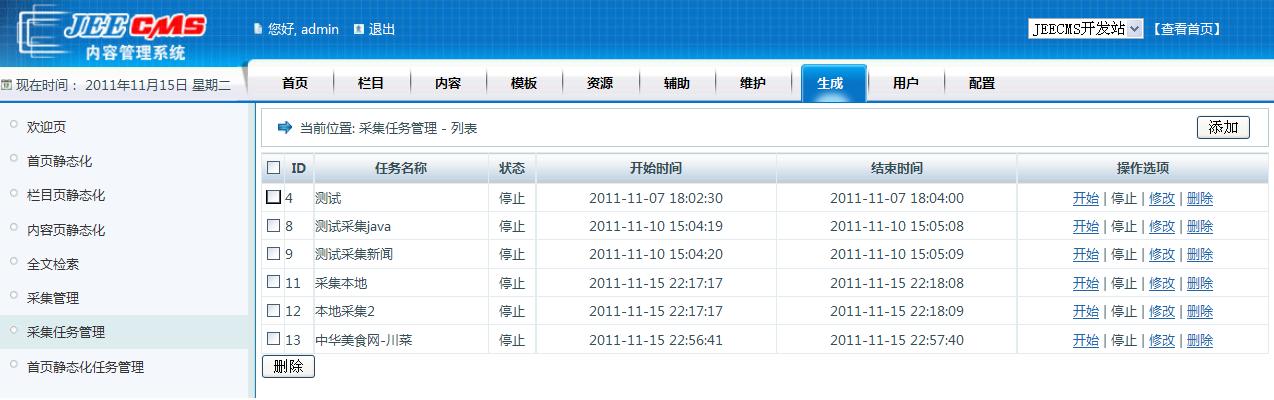
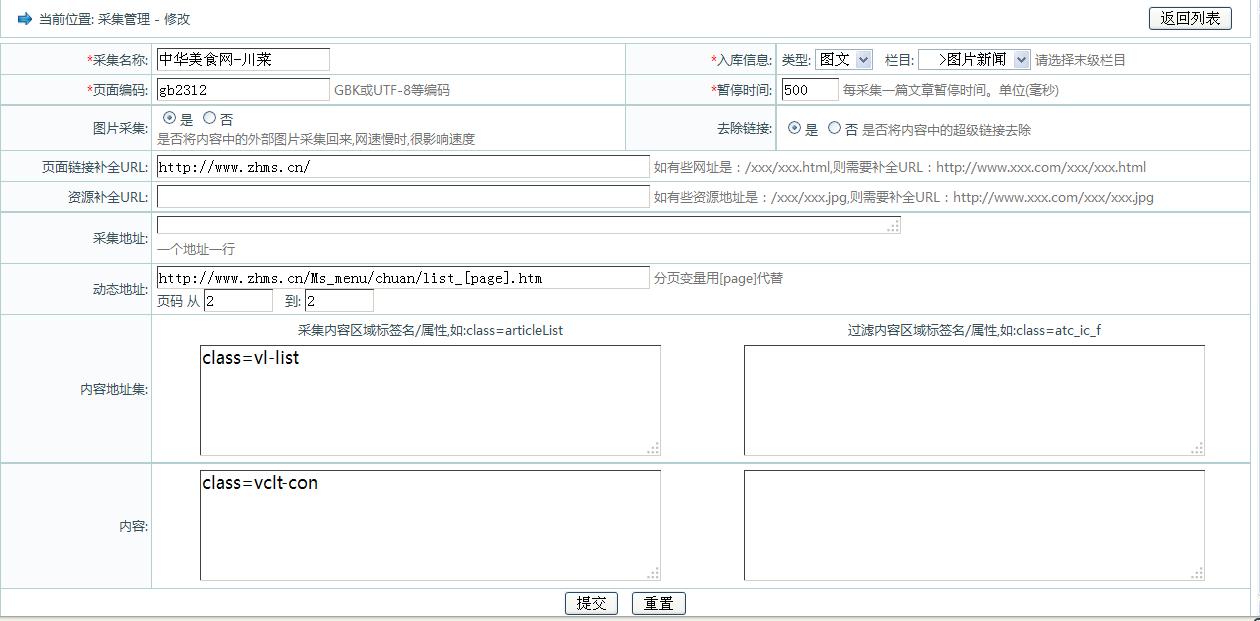
以下是管理界面及参数设置界面:


=====================================================================
* 爬虫工作流程如下:<br>
* 一:根据initialize传递进来的CrawlScope对象初始化爬虫各个模块,分别是爬虫的配置参数,字符集帮助类,初始化HttpCilent对象,HTML解析器帮助类,边界控制器,线程控制器和处理器链<br>
* 1:爬虫配置参数(CrawlScope):存储当前爬虫的配置信息,如采集页面编码,采集过滤器列表,采集种子列表,爬虫持久对象实现类<br>
* 2:字符集帮助类(CharsetHandler):字符集帮助类<br>
* 3:初始化HttpCilent对象:初始化HttpCilent对象<br>
* 4:HTML解析器帮助类(ParseHtmlTool):根据爬虫配置参数(CrawlScope)中采集过滤器列表初始化HTML解析器<br>
* 5:边界控制器(Frontier):主要是加载爬行种子链接并根据加载的种子链接初始化任务队列,以备线程控制器(ProcessorThreadPool)开启的任务执行线程(ProcessorThread)使用<br>
* 6:线程控制器(ProcessorThreadPool):主要是控制任务执行线程数量,开启指定数目的任务执行线程执行任务<br>
* 7:处理器链(ProcessorChainList):默认构建了5中处理链,依次是,预取链,提取链,抽取链,写链,提交链,在任务处理线程中将使用<br>
* 二:调用爬虫控制器start方法启动爬虫。
说明:采集参数设置不变,请参考前几篇文章。
* <li>约定采集参数格式如下</li>
* <li>1,标签属性/值形式,如:class=articleList|tips,id=fxwb|fxMSN|fxMSN</li>
* <li>2,标签名称形式,如:div,p,span</li>
* <li>3,混合形式,如:class=articleList|tips,id=fxwb|fxMSN|fxMSN,div,p,span</li>
调用代码:
package com.jeecms.cms.service.scheduler;
import java.util.ArrayList;
import java.util.List;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.jeecms.cms.entity.assist.CmsAcquisition;
import com.jeecms.cms.entity.assist.CmsScheduler;
import com.jeecms.cms.manager.assist.CmsAcquisitionMng;
import com.jeecms.common.crawler.CrawlController;
import com.jeecms.common.crawler.data.CrawlScope;
import com.jeecms.common.crawler.filter.ContentAreaFilter;
import com.jeecms.common.crawler.filter.Filter;
import com.jeecms.common.crawler.filter.LinkAreaFilter;
import com.jeecms.common.crawler.persistent.CrawlerPersistent;
/**
* 计划任务接口-采集器实现类-多线程版
* @author javacoo
* @since 2011-11-02
* @version 1.0
*/
@Service
public class SchedulerAcquisitionSvcImpl extends AbstractSchedulerTaskSvc {
private Logger log = LoggerFactory.getLogger(SchedulerAcquisitionSvcImpl.class);
/**采集管理对象*/
private CmsAcquisitionMng cmsAcquisitionMng;
/**爬虫持久化对象*/
private CrawlerPersistent crawlerPersistent;
@Autowired
public void setCmsAcquisitionMng(CmsAcquisitionMng cmsAcquisitionMng) {
this.cmsAcquisitionMng = cmsAcquisitionMng;
}
@Autowired
public void setCrawlerPersistent(CrawlerPersistent crawlerPersistent) {
this.crawlerPersistent = crawlerPersistent;
}
@Override
protected boolean execute(CmsScheduler scheduler) {
CmsAcquisition acqu = cmsAcquisitionMng.findById(scheduler.getAssociateId());
if (acqu == null) {
return false;
}
CrawlController crawlController = new CrawlController();
List<Filter> filters = new ArrayList<Filter>();
filters.add(new LinkAreaFilter(acqu.getLinksetStart(),acqu.getLinksetEnd()));
filters.add(new ContentAreaFilter(acqu.getContentStart(),acqu.getContentEnd()));
CrawlScope crawlScope = new CrawlScope();
crawlScope.setCrawlerPersistent(crawlerPersistent);
crawlScope.setEncoding(acqu.getPageEncoding());
crawlScope.setId(acqu.getId());
crawlScope.setFilterList(filters);
crawlScope.setRepairPageUrl("http://www.zhms.cn/");
//是否下载图片至本地
crawlScope.setReplaceHtmlImage(true);
//是否去掉内容中连接
crawlScope.setReplaceHtmlLink(true);
crawlScope.addSeeds(acqu.getAllPlans());
crawlController.initialize(crawlScope);
crawlController.start();
return true;
}
/**
* 取得关联任务map
* @return 关联任务map
*/
public List<SchedulerTaskBean> associateTaskList(CmsScheduler scheduler){
List<CmsAcquisition> list = cmsAcquisitionMng.getList(scheduler.getSite().getId());
List<SchedulerTaskBean> resultList = new ArrayList<SchedulerTaskBean>();
SchedulerTaskBean schedulerTaskBean = null;
for(CmsAcquisition acquisition : list){
schedulerTaskBean = new SchedulerTaskBean();
schedulerTaskBean.setId(acquisition.getId());
schedulerTaskBean.setName(acquisition.getName());
resultList.add(schedulerTaskBean);
}
return resultList;
}
}
package com.jeecms.cms.service.scheduler;
import java.util.Iterator;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.jeecms.cms.manager.assist.CmsAcquisitionMng;
import com.jeecms.common.crawler.data.ContentBean;
import com.jeecms.common.crawler.persistent.CrawlerPersistent;
/**
* 爬虫持久层接口实现类
* @author javacoo
* @since 2011-11-12
*/
@Service
public class SimpleCrawlerPersistentImpl implements CrawlerPersistent{
/**采集管理对象*/
private CmsAcquisitionMng cmsAcquisitionMng;
@Autowired
public void setCmsAcquisitionMng(CmsAcquisitionMng cmsAcquisitionMng) {
this.cmsAcquisitionMng = cmsAcquisitionMng;
}
/**
* 保存内容
* @param contentBean
*/
public synchronized void save(ContentBean contentBean) {
int imagesMapSize = contentBean.getImagesMap().keySet().size();
String[] imagesPath = new String[imagesMapSize];
String[] imagesDesc = new String[imagesMapSize];
int i = 0;
for(Iterator<String> it = contentBean.getImagesMap().keySet().iterator();it.hasNext();){
imagesPath[i] = it.next();
imagesDesc[i] = "";
i++;
}
cmsAcquisitionMng.saveContent(contentBean.getTitle(), contentBean.getContent(),contentBean.getBrief(),imagesPath,imagesDesc, contentBean.getAcquId());
}
}
jeecms-context.xml 加上
<bean id="simpleCrawlerPersistent" class="com.jeecms.cms.service.scheduler.SimpleCrawlerPersistentImpl"/>
修改了 CmsAcquisitionMng.java 接口 及其实现类 CmsAcquisitionMngImpl.java 中 saveContent方法 :
public Content saveContent(String title, String txt,String description,String[] picPaths,String[] imagesDesc, Integer acquId);
加上了,摘要,图片集,
实现类中方法:
public Content saveContent(String title, String txt,String description,String[] picPaths,String[] imagesDesc, Integer acquId) {
CmsAcquisition acqu = findById(acquId);
Content c = new Content();
c.setSite(acqu.getSite());
ContentExt cext = new ContentExt();
ContentTxt ctxt = new ContentTxt();
cext.setTitle(title);
cext.setDescription(description);
ctxt.setTxt(txt);
return contentMng.save(c, cext, ctxt, null, null, null, null, null,
null, null, picPaths, imagesDesc, acqu.getChannel().getId(), acqu
.getType().getId(), false, acqu.getUser(), false);
}
爬虫代码:
放在common包下
crawler.rar
继续完善中,请大家提出宝贵意见,谢谢:)
|
|










